Canvas LMS Cheat Detection System In Python
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello All!
What it is:
I've been working on a program to separate test users into groups of cheaters and non-cheaters on Canvas quizzes. It's still being developed. However, I've made enough to have a test version for people to download and try now here. I thought this may be interesting for some teachers if anyone finds time to test this program out, let me know! I'm very limited in developing this, as I'm a student that has little to no data-sets.
There are some quirks (especially concerning certain network connections, see the repository readme for more details on that).
How it works:
This will be a bit more technical, but I will try to explain it as clear as I possibly can, using code examples where appropriate. It may be helpful to look at the code here.
Firstly this is not an instant flagging program that only looks at the number of times a user leaves the page. My assumption is that a student may accidentally hit alt-tab, change the music they are listening to without realizing that they leave the page or some other mishap with how Canvas' javascript tracks page leaves. (I have had a case where Canvas has that a user left the page at the end of a test as the final event and not a page return event). Instead, this program uses unsupervised Machine Learning and Deep Learning to separate cheaters and non-cheaters.
However, before any of that, the data has to be gathered from the test (quiz):
gatherer = Quiz(class_id=class_id, quiz_id=quiz_id, url=url, header=header)
constructor = QuizEvents(gatherer, anon=False)
The Quiz and QuizEvents classes are found in the collectors and constructors files respectively. The Quiz contains the functions that either read already made .json files or create them based on the quiz data. It separates them into valuable data that can be fed into the constructor class. The constructor class uses the Quiz class to get the separated data and load it into a dictionary:
def _build_user_scores(self😞
"""Adds the user score as a feature to the current data set
"""
score_list = []
for submit in self.submissions:
current_points = submit['kept_score']
current_points_possible = submit['quiz_points_possible']
current_score = round(current_points/current_points_possible, 2)
user_id = str(submit['user_id'])
score_list.append(current_score)
self.data_set[user_id]['score'] = current_score
overall_average = round(sum(score_list) / len(score_list), 2)
self.data_set['Overall']['score'] = overall_average
Eventually, once all the data is built, it's put into a panda's data frame to be later fed into a tensorflow implementation of an auto-encoder.
def build_dataframe(self, pre_flagged=False😞
"""Builds a dataframe based on the current data set
:return: Pandas dataframe containing input data
"""
# Creates a copy to preserve the integrity of the overall data in the data_set variable
data_set_copy = self.data_set.copy()
del self.data_set['Overall']
data_set = self.data_set
self.data_set = data_set_copy
del data_set_copy
data_frame = pd.DataFrame.from_dict(data_set, orient='index')
pre_flags = data_frame.loc[data_frame['page_leaves'] == 'CA']
data_frame.drop(data_frame.loc[data_frame['page_leaves'] == 'CA'].index.values, inplace=True)
if pre_flagged:
return pre_flags, data_frame
else:
return data_frame
There are a few things to explain here. Firstly, to keep the original dictionary in-tact, it does some python magic with copying it to a temporary value. This allows other functions within the class to retain their functionality by accessing the data from the constructor - mostly a development feature, but still of note.
Secondly, the pre_flagged parameter. This pre flags students who have page_leaves that are unreasonably high. Without question, without running it through any type of Machine Learning, it clearly can be seen that this person left the page far too much. Note here: if pre_flagged is called with it set to False there will be an error and the pre_flag threshold right now is simply 10, which reflect the data I have been testing on. Both of this will be modified at a later date.
Once the data set has been built, dimensionality reduction in the form of scikit-learn's PCA is performed and then it is fed into an Auto-Encoder, something that is typically used as a pre-training system for deep neural networks, but in this case, it's used an anomaly detection system. The idea behind an Auto-Encoder is something that learns the structure of the data, compresses or encodes it, and then decompresses or de-encode it. Using traditional back-propagation to learn weights for the features, it can be shown that an Auto-Encoder that has been trained on a specific data-set can separate anomalies out of a data-set. The code for this is long and more spaghetti-like then I prefer, so I think this image of the auto-encoder will be a better display. Here, it's using an image for the example, but the same concept applies to regular numeric data as well:
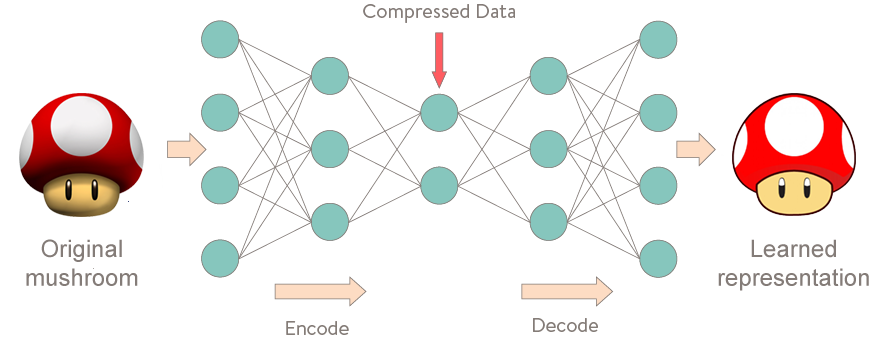
For more information about how this Auto-Encoder separates the data, see here for a video using a similar method to detect cheaters in mobile games, and here for the code of the Auto-Encoder's separation function.
Finally, the scikit-learn implementation of KMeans is used to look at the anomalous data. KMeans is unsupervised clustering, which groups together similar data into classes. The number of classes can be provided to the algorithm, however, in this case, the assume the class number is two. This is because the data separated from the Auto-Encoder will, without exception, contain high-performing and low-performing student, regardless of if they cheated or not. This is where clustering comes into play. There is an assumption made, that being cheaters will look similar, which has so far shown to be a somewhat sound assumption. While I've been testing with this, I've been trying it with features enabled and disabled, to see what type of data is good at indicating if someone is cheating or not. In this case, the actual score someone made on a test doesn't appear to be a good indicator of a cheater. This is because, while yes, there are extreme cheaters who cheat on the entire test, there are also non-extremes who only cheat on a few questions, and that makes up the majority of cheaters, from what I've seen at least.
The KMeans will be fairly accurate regarding separating cheaters from non-cheaters. However, then the identification process of which cluster is supposed to represent cheaters and which one is supposed to be non-cheaters begins. The current process takes the average number of page leaves from one class and compares it to another. This is a fairly robust method in many cases, for one, it guarantees if a cheater is flagged as non-cheating, taking the average (in which page_leaves will be next to or exactly 0 for non-cheaters) will keep non-cheaters as non-cheaters, even if it increases false-positives (cheaters grouped with non-cheaters). Though there are problems with this method, especially when only cheaters are separated as anomalies before KMeans even begins, in which case there is guaranteed to be false flags. A more robust method is in the works.
Once all this is done, the distance for each KMeans item from the assigned and distant cluster is calculated.

The numbers here represent user ids (this can be changed to names with anon=False when building the constructors)
OD being Opposite cluster distance
AD being Assigned cluster distance
(These are both calculated with euclidian distance, though, another metric may replace this in the future, given that higher-dimensional data-sets may come into play once more features to describe cheaters have been developed).
